One of the most persistent bottlenecks in supply chain digitization is the reliance on unstructured, read-only PDF files. We partnered with Fung Academy to engineer a scalable solution: automating the extraction of complex data and sketches from tech packs using a parallel microservices architecture.
The Extraction Pipeline
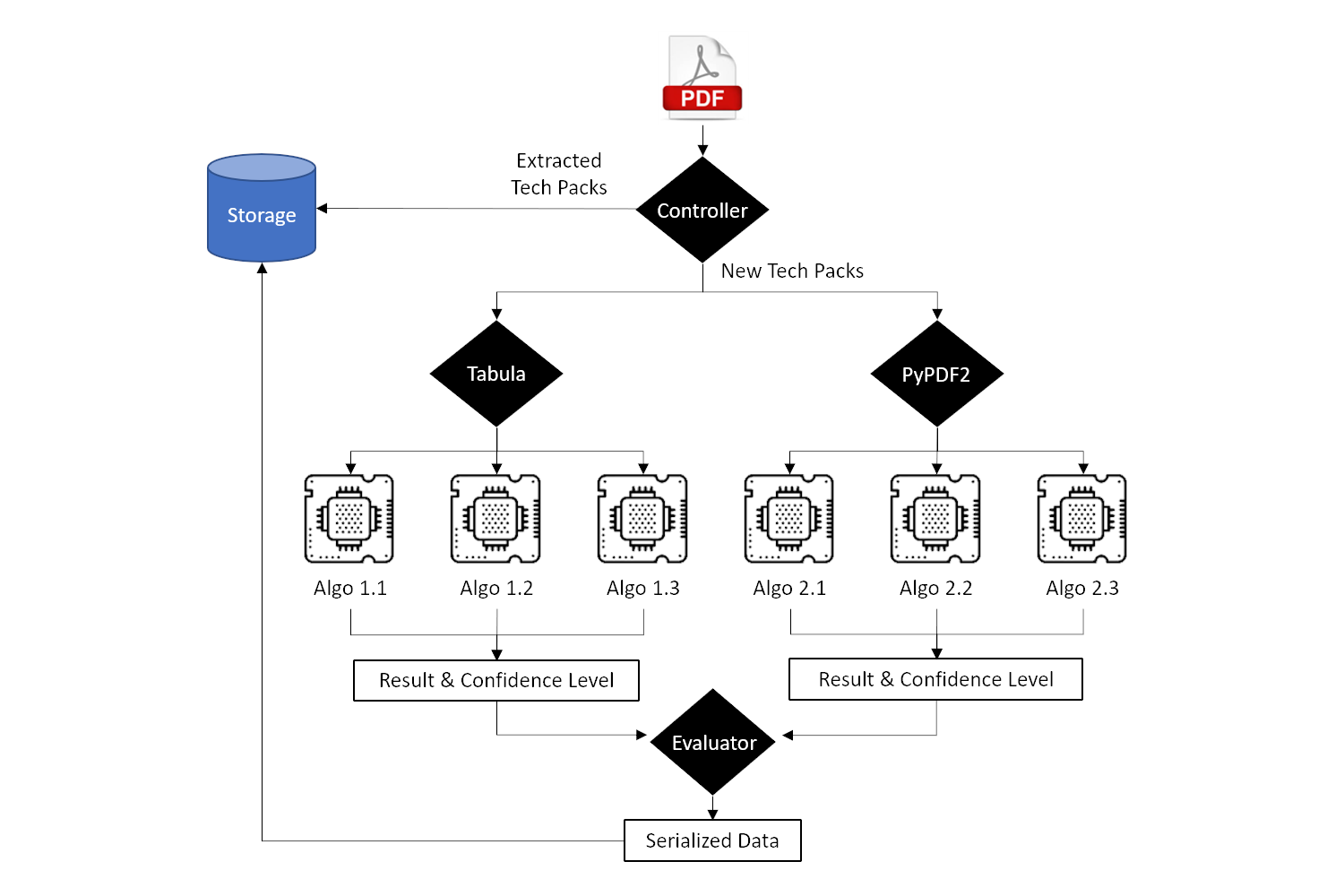
When tech packs (in PDF format) enter the architecture, a central controller first validates whether the document has been previously processed. If it is a new file, the system executes a raw data extraction using Python libraries such as Tabula and PyPDF2.
Because tech packs contain highly variable structures, these raw extracts are instantly routed through a series of parallel microservices. Each algorithmic service specializes in interpreting and reconstructing specific data fragments, transforming unstructured text into clean, actionable datasets.
Evaluation and Serialization
This confidence scoring mechanism ensures that only high-fidelity data advances to the evaluation node. The evaluation layer aggregates the outputs from the various parallel microservices, resolving conflicts and finalizing the extracted information.
Once validated, the data is serialized and pushed to a designated database, where it becomes immediately available for downstream processing, analytics, or export to third-party enterprise systems.
A Scalable Foundation
The true power of this architecture lies in its modularity. Because it is built on independent microservices, the system can be infinitely expanded. We can continuously deploy new algorithms specialized in extracting entirely new categories of data—such as advanced product classifications or intricate design sketches. Ultimately, this structured data acts as the foundation for optimizing complex vendor management activities, from capability development to highly accurate capacity allocation.